基于语雀 API 的文档管理探索
一直以来都有不少人在纠结语雀文档的批量导出,殊不知语雀本身提供了相当丰富的 API —— 这些 API 正好可以帮助我们实现个人知识库的批量化导入导出和备份的目的。 开发者文档
基于 API 的应用¶
语雀开发者文档 —— https://www.yuque.com/yuque/developer/api 的评论区列了不少基于 API 的应用和案例,感兴趣的可以去细看,这里简单列举几个个人觉得比较具有代表性的。
- Node SDK:https://github.com/yuque/sdk
- 回馈一个 Python SDK & 命令行工具:juq
- 回馈一个同步仓库文章到本地的命令行工具:yuque-hexo
- 回馈一个 Py:https://github.com/Xarrow/simple-pyyuque
- 用 go 写的 SDK https://github.com/my-Sakura/go-yuque-api
- 语雀 Java sdk :https://github.com/ryangsun/yuque-java-sdk
- 补充一个 Python 的导出本地备份:https://github.com/shenweiyan/YQExportMD
个人比较熟悉 Python,所以会对基于 Python 的一些 API 进行尝试和说明。
API 操作与说明¶
获取个人的所有知识库¶
import requests
headers = {
"Content-Type": "application/json",
"User-Agent": ""Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
"X-Auth-Token": 'XJ..........PQCoJtjrIO'
}
response = requests.request(method='GET', url='https://www.yuque.com/api/v2/users/shenweiyan/repos', headers=headers)
response.json()
Out[16]:
{'data': [{'id': 227777,
'type': 'Book',
'slug': 'cookbook',
'name': '技术私房菜',
'user_id': 126032,
'description': '原创技术文章,记录工作,学习的知识汇总。',
'creator_id': 126032,
'public': 1,
'items_count': 218,
'likes_count': 0,
'watches_count': 182,
'content_updated_at': '2022-12-02T07:27:32.714Z',
'updated_at': '2022-12-02T07:27:33.000Z',
'created_at': '2019-03-01T12:22:24.000Z',
'namespace': 'shenweiyan/cookbook',
'user': {'id': 126032,
'type': 'User',
'login': 'shenweiyan',
'name': '章鱼猫先生',
'description': '乐于分享,爱好码字,沉迷于折腾 | Bio & IT 爱好者',
'avatar_url': 'https://cdn.yuque.com/yuque/0/2018/jpeg/126032/1526460304504-avatar/f6903e58-a5ec-4c79-9d61-f8c8e0e3f83c.jpeg',
'followers_count': 765,
'following_count': 95,
'created_at': '2018-05-16T08:29:24.000Z',
'updated_at': '2022-12-02T07:44:57.000Z',
'_serializer': 'v2.user'},
'_serializer': 'v2.book'},
{'id': 174556,
'type': 'Book',
'slug': 'own',
'name': '杂文私房菜',
.....
},
......
}
获取某个知识库内所有文档¶
url = "https://www.yuque.com/api/v2/repos/227777/docs" # 227777 为对应知识库的 repo_id
resp = requests.request("GET", url, headers=headers)
repo_docs = resp.json() # 得到一个以 data 为 key 的字典
docs = repo_docs['data'] # 返回一个包含该知识库所有文档的 list
In [20]: docs[0].keys() # 每个 list 是一个包含了 27 个 key 的字典
Out[20]: dict_keys(['id', 'slug', 'title', 'description', 'user_id', 'book_id', 'format', 'public', 'status', 'view_status', 'read_status', 'likes_count', 'read_count', 'comments_count', 'content_updated_at', 'created_at', 'updated_at', 'published_at', 'first_published_at', 'draft_version', 'last_editor_id', 'word_count', 'cover', 'custom_description', 'last_editor', 'book', '_serializer'])
获取某个指定文档的内容¶
基于 API¶
最终的doc['data']['body']即为对应文章正文内容。
repo_id, slug = "227777", "webstack-hugo"
url = "https://www.yuque.com/api/v2/repos/%s/docs/%s" % (repo_id, slug)
res = requests.request("GET", url, headers=headers)
doc = res.json() # 返回一个包含 ['abilities', 'data'] 2 个 key 的字典
In [30]: doc.keys()
Out[30]: dict_keys( ['abilities', 'data']
In [31]: doc['data'].keys()
Out[31]: dict_keys(['id', 'slug', 'title', 'book_id', 'book', 'user_id', 'creator', 'format', 'body', 'body_draft', 'body_html', 'body_lake', 'body_draft_lake', 'public', 'status', 'view_status', 'read_status', 'likes_count', 'comments_count', 'content_updated_at', 'deleted_at', 'created_at', 'updated_at', 'published_at', 'first_published_at', 'word_count', 'cover', 'description', 'custom_description', 'hits', '_serializer'])
In [26]: doc
Out[26]:
{'abilities': {'update': True, 'destroy': True},
'data': {'id': 49148406,
'slug': 'webstack-hugo',
'title': 'WebStack-Hugo | 一个静态响应式网址导航主题',
'book_id': 227777,
'book': {'id': 227777,
'type': 'Book',
'slug': 'cookbook',
'name': '技术私房菜',
'user_id': 126032,
'description': '原创技术文章,记录工作,学习的知识汇总。',
'creator_id': 126032,
'public': 1,
'items_count': 218,
'likes_count': 0,
'watches_count': 182,
'content_updated_at': '2022-12-02T07:27:32.714Z',
'updated_at': '2022-12-02T07:27:33.000Z',
'created_at': '2019-03-01T12:22:24.000Z',
'namespace': 'shenweiyan/cookbook',
'user': {'id': 126032,
'type': 'User',
'login': 'shenweiyan',
'name': '章鱼猫先生',
'description': '乐于分享,爱好码字,沉迷于折腾 | Bio & IT 爱好者',
'avatar_url': 'https://cdn.yuque.com/yuque/0/2018/jpeg/126032/1526460304504-avatar/f6903e58-a5ec-4c79-9d61-f8c8e0e3f83c.jpeg',
'books_count': 27,
'public_books_count': 12,
'followers_count': 765,
'following_count': 95,
'created_at': '2018-05-16T08:29:24.000Z',
'updated_at': '2022-12-02T07:44:57.000Z',
'_serializer': 'v2.user'},
'_serializer': 'v2.book'},
'user_id': 126032,
'creator': {'id': 126032,
'type': 'User',
'login': 'shenweiyan',
'name': '章鱼猫先生',
'description': '乐于分享,爱好码字,沉迷于折腾 | Bio & IT 爱好者',
'avatar_url': 'https://cdn.yuque.com/yuque/0/2018/jpeg/126032/1526460304504-avatar/f6903e58-a5ec-4c79-9d61-f8c8e0e3f83c.jpeg',
'books_count': 27,
'public_books_count': 12,
'followers_count': 765,
'following_count': 95,
'created_at': '2018-05-16T08:29:24.000Z',
'updated_at': '2022-12-02T07:44:57.000Z',
'_serializer': 'v2.user'},
'format': 'lake',
'body': ':::tips\n**📢 如果您参考本主题构建了属于你自己的网址导航,欢迎在评论区留下你网站的访问链接。**\n:::\......
.....
不用 API¶
如果我们知道语雀某一篇公开文档的链接,如 https://www.yuque.com/yuque/developer/api,我们可以在该 url 后增加 “/markdown?plain=true\&linebreak=false\&anchor=false”,即可在浏览器直接查阅该文档的 markdown 格式内容。
https://www.yuque.com/yuque/developer/api/markdown?plain=true&linebreak=false&anchor=false
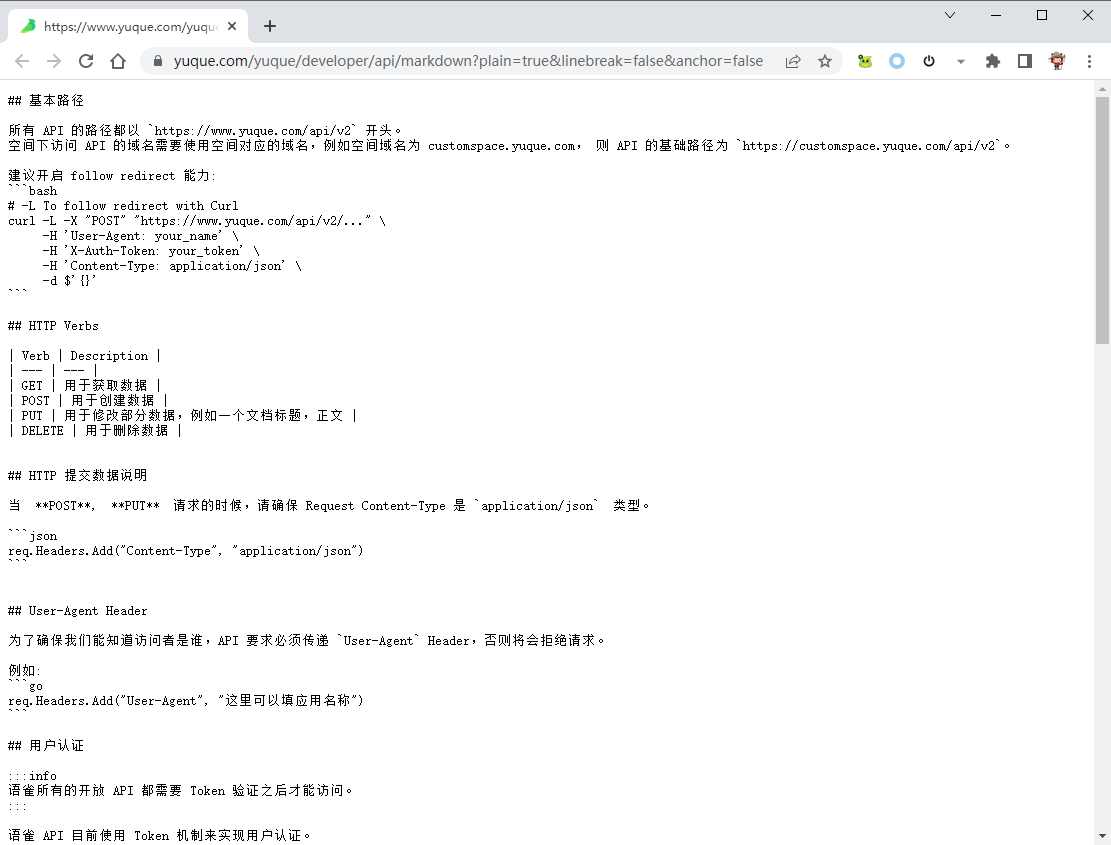 接下来的操作就很简单了,我们可以直接复制该 markdown 内容,或者用程序直接抓取下来。
接下来的操作就很简单了,我们可以直接复制该 markdown 内容,或者用程序直接抓取下来。
In [46]: res = requests.request("GET", 'https://www.yuque.com/yuque/developer/api/markdown?plain=true&linebreak=false&anchor=false', headers=headers)
In [47]: res.text
Out[47]: '## 基本路径\n\n所有 API 的路径都以 `https://www.yuque.com/api/v2` 开头。\n空间下访问 API 的域名需要使用空间对应的域名,例如空间域名为 customspace.yuque.com, 则 API 的基础路径为 `https://customspace.yuque.com/api/v2`。\n\n建议开启 follow redirect 能力:\n```bash\n# -L To follow redirect with Curl\ncurl -L -X "POST" "https://www.yuque.com/api/v2/..." \\\n -H \'User-Agent: your_name\' \\\n -H \'X-Auth-Token: your_token\' \\\n -H \'Content-Type: application/json\' \\\n -d $\'{}\'\n```\n\n## HTTP Verbs\n\n| Verb | Description |\n| --- | --- |\n| GET | 用于获取数据 |\n| POST | 用于创建数据 |\n| PUT | 用于修改部分数据,例如一个文档标题,正文 |\n| DELETE | 用于删除数据 |\n\n\n## HTTP 提交数据说明\n\n当\xa0**POST**,\xa0**PUT**\xa0请求的时候,请确保 Request Content-Type 是 `application/json`\xa0类型。\n\n```json\nreq.Headers.Add("Content-Type", "application/json")\n```\n\n\n## User-Agent Header\n\n为了确保我们能知道访问者是谁,API 要求必须传递 `User-Agent` Header,否则将会拒绝请求。\n\n例如:\n```go\nreq.Headers.Add("User-Agent", "这里可以填应用名称")\n```\n\n## 用户认证\n\n:::info\n语雀所有的开放 API 都需要 Token 验证之后才能访问。\n:::\n\n语雀 API 目前使用 Token 机制来实现用户认证。\n\n你需要在请求的 HTTP Headers 传入 `X-Auth-Token` 带入用户的 Token 信息,用于认证。\n\n获取 Token 可通过点击语雀的个人头像,并进入\xa0[个人设置](/settings/tokens)\xa0页面拿到,如下图:\n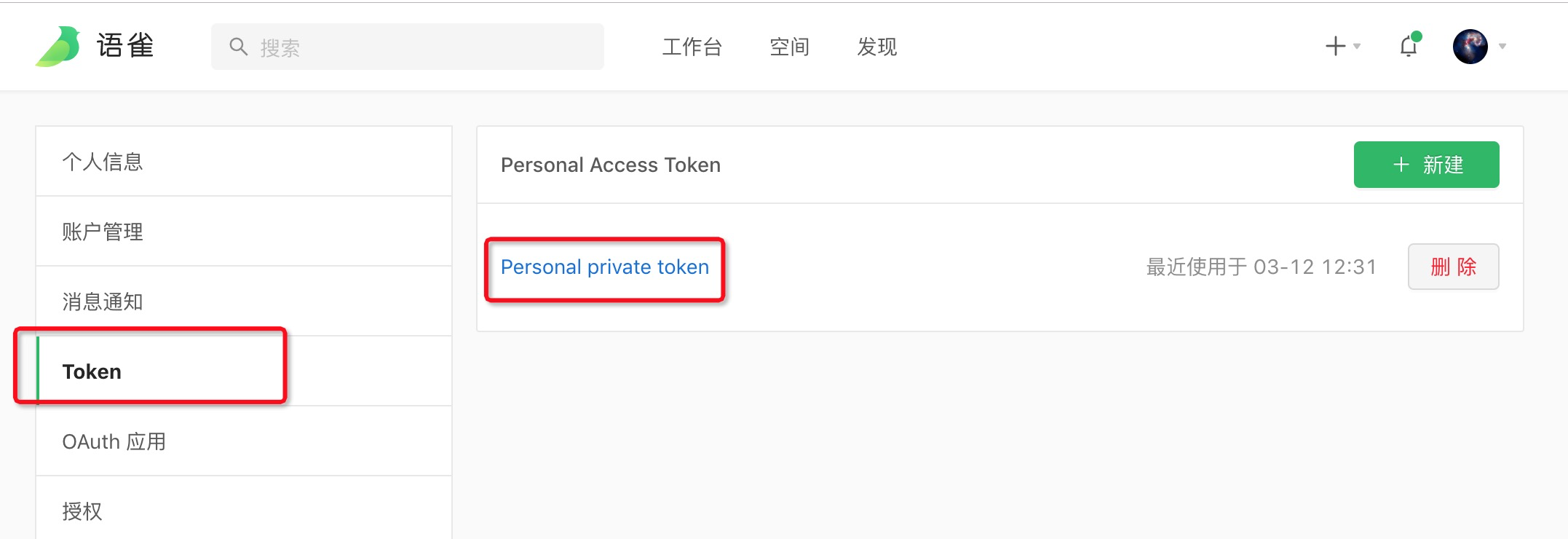\n\n\n**For example**\n```bash\ncurl -H "X-Auth-Token: gCmkIlgAtuc3vFwpLfeM1w==" https://www.yuque.com/api/v2/hello\n```\n\n**Response**\n```json\n{\n "data":{\n "message":"Hello 小明"\n }\n}\n```\n\n`X-Auth-Token` 依据用户有的权限,决定了能获取到的数据,例如,假如 “小明” 这个账号是 “[语雀/帮助](/yuque/help)” 这个文档仓库的 `Owner`,那么通过他的 Token 可以获取到这个仓库的所有信息。\n\n其他情况由具体的功能权限设定来决定能获取到什么样的数据,以及那些数据有修改权限,详见后面 API 的具体接口返回的 `abilities` 描述。\n\n## HTTP 状态码\n\n- 200 - 成功\n- 400 - 请求的参数不正确,或缺少必要信息,请对比文档\n- 401 - 需要用户认证的接口用户信息不正确\n- 403 - 缺少对应功能的权限\n- 404 - 数据不存在,或未开放\n- 500 - 服务器异常\n\n## 参数说明\n| Name | Description | Example |\n| --- | --- | --- |\n| id | 数据的唯一编号/主键 | 1984 |\n| login | 用户/团队的唯一名称\n用户/团队编号 | 用户:用户个人路径\n团队:如[语雀团队](/yuque),login 值为 `yuque` |\n| book_slug | 仓库唯一名称 | 如[语雀开发者文档](/yuque/developer)这个仓库,`book_slug` 值为 `developer`** ** |\n| namespace | 仓库的唯一名称\n需要组合\xa0`:login/:book_slug`\n或可以直接使用仓库编号 | `yuque/developer` |\n| slug | 文档唯一名称 | 如[当前这篇文档](/yuque/developer/api)的 slug 值为 `api` |\n\n## 返回数据格式\n\n- JSON 格式\n\n```json\n{\n "data": {\n "id": 10,\n "slug": "weekly",\n "name": "技术周刊",\n "abilities": {\n "update": false,\n "destroy": false\n }\n },\n "meta": {\n "liked": false,\n "followed": false,\n }\n}\n```\n\n- id: 每个数据都会有的,Resource 的唯一编号,后续很多地方你可能需要用它查询\n- abilities: 表述当前登陆者对于此资源的权限\n- meta: 一些附加信息,例如是否赞过,是否关注过\n\n## Rate Limit 访问频率限制\n\n- 匿名请求,IP 限制, 200 次/小时\n- 传递 Token 的情况下,每个用户(基于 Token 关联到的账户),5000 次/小时;\n\n每次请求 `Response Header` 将会返回频率限制的信息,例如:\n\n```\nX-RateLimit-Limit: 100\nX-RateLimit-Remaining: 75\n```\n\n- `X-RateLimit-Limit` - 总次数\n- `X-RateLimit-Remaining` - 剩余次数\n\n如果超过限制,将会返回:\n\n```\nHTTP/1.1 429 Too Many Requests\n```\n\n## DateTime 格式\nDateTime 使用\xa0[ISO 8601](https://en.wikipedia.org/wiki/ISO_8601)\xa0标准格式,请按照标准方式进行转换。\n'
In [48]:
语雀图片备份处理¶
语雀的图片可以直接下载到本地(参考:https://github.com/shenweiyan/YQExportMD),或者使用镜像回源的方式直接转存到阿里云/腾讯云.....的对象存储中(参考:语雀图片的同步迁移解决方案),这里暂时不展开。
写在最后¶
基于 API 的语雀文章备份/导出,对于 markdown 的文档是一个不错的解决方案,但对于数据表、小记和其他一些记录则不适用,目前也暂时没有更好的方案。
所以,如果你使用语雀作为你的 markdown 博客平台,只要 API 还在备份目前是不需要担心的!